AWS Inventory Extraction using CloudQuery
Extract your multi-account AWS inventory using CloudQuery
 CloudQuery
CloudQuery
Introduction
I wanted to extract the AWS Inventory spread out over multiple regions and accounts. Offcourse there are many solutions and different ways to do this but in this post I’d like to share how I was able to do this using an opensource tool called as CloudQuery
To put in extremely simple words , CloudQuery converts your Cloud(AWS,GCP and many more) asset information into a SQL Database. For Ex: Below are the columns for the table storing information about your EC2 instances
cq_id,cq_meta,account_id,region,arn,state_transition_reason_time,ami_launch_index,architecture,boot_mode,capacity_reservation_id,cap_reservation_preference,cap_reservation_target_capacity_reservation_id,cap_reservation_target_capacity_reservation_rg_arn,client_token,cpu_options_core_count,cpu_options_threads_per_core,ebs_optimized,ena_support,enclave_options_enabled,hibernation_options_configured,hypervisor,iam_instance_profile_arn,iam_instance_profile_id,image_id,id,instance_lifecycle,instance_type,kernel_id,key_name,launch_time,licenses,metadata_options_http_endpoint,metadata_options_http_protocol_ipv6,metadata_options_http_put_response_hop_limit,metadata_options_http_tokens,metadata_options_state,monitoring_state,outpost_arn,placement_affinity,placement_availability_zone,placement_group_name,placement_host_id,placement_host_resource_group_arn,placement_partition_number,placement_spread_domain,placement_tenancy,platform,private_dns_name,private_ip_address,public_dns_name,public_ip_address,ramdisk_id,root_device_name,root_device_type,source_dest_check,spot_instance_request_id,sriov_net_support,state_code,state_name,state_reason_code,state_reason_message,state_transition_reason,subnet_id,tags,virtualization_type,vpc_id
With the power of SQL, possibilities of utilising this data is endless as an example, if you’d like to identify which EC2 instances are still using IMDSv1 then simply fire the query as
select * from aws_ec2_instances where metadata_options_http_tokens = 'optional' ;
Pre-Requisites
- A PostgreSQL database. Below command can be used to quickly spin one up using docker.
docker run --name cloudquery_postgres -p 5432:5432 -v ${PWD}:/tmp -e POSTGRES_PASSWORD=pass -d postgres
- A PostgreSQL Administrator tool that can connect to the PGSQL database that we’ll spin up
- AWS Access Keys configure in ~/.aws/credentials
- CloudQuery
NOTE: We are setting up a test bed here and not a production-grade solution.
Configuration
Configuring CloudQuery is quite straightforward and can be easily followed through this link https://docs.cloudquery.io/docs/getting-started/getting-started-with-aws for AWS.
Once CloudQuery has been initialised we need to edit the config.hcl file which cloudquery will read in order to fetch the details.
A sample config.hcl file is as shown below.
The accounts configured must match the different aws profiles configured in ~/.aws/credentials file.
// Configuration AutoGenerated by CloudQuery CLI
cloudquery {
plugin_directory = "./cq/providers"
policy_directory = "./cq/policies"
provider "aws" {
version = "latest"
}
// Ensure the credentials match to that of the docker command provided above.
connection {
dsn = "postgres://postgres:pass@localhost:5432/postgres?sslmode=disable"
}
}
// All Provider Configurations
provider "aws" {
configuration {
// Configuring the different accounts.
accounts "dev" {
local_profile = "example-dev"
}
accounts "prod" {
local_profile = "example-prod"
}
accounts "staging" {
local_profile = "example-staging"
}
// Optional. by default assumes all regions
// regions = ["us-east-1", "us-west-2"]
// Optional. Enable AWS SDK debug logging.
aws_debug = false
// The maximum number of times that a request will be retried for failures. Defaults to 5 retry attempts.
// max_retries = 5
// The maximum back off delay between attempts. The backoff delays exponentially with a jitter based on the number of attempts. Defaults to 60 seconds.
// max_backoff = 30
}
// list of resources to fetch
resources = [
"accessanalyzer.analyzers",
"acm.certificates",
"apigateway.api_keys",
"apigateway.client_certificates",
"apigateway.domain_names",
"apigateway.rest_apis",
"apigateway.usage_plans",
"apigateway.vpc_links",
"apigatewayv2.apis",
"apigatewayv2.domain_names",
"apigatewayv2.vpc_links",
"applicationautoscaling.policies",
"autoscaling.groups",
"autoscaling.launch_configurations",
"aws.regions",
"cloudfront.cache_policies",
"cloudfront.distributions",
"cloudtrail.trails",
"cloudwatch.alarms",
"cloudwatchlogs.filters",
"codebuild.projects",
"cognito.identity_pools",
"cognito.user_pools",
"config.configuration_recorders",
"config.conformance_packs",
"dax.clusters",
"directconnect.connections",
"directconnect.gateways",
"directconnect.lags",
"directconnect.virtual_gateways",
"directconnect.virtual_interfaces",
"dms.replication_instances",
"dynamodb.tables",
"ec2.byoip_cidrs",
"ec2.customer_gateways",
"ec2.ebs_snapshots",
"ec2.ebs_volumes",
"ec2.eips",
"ec2.flow_logs",
"ec2.images",
"ec2.instances",
"ec2.internet_gateways",
"ec2.nat_gateways",
"ec2.network_acls",
"ec2.regional_config",
"ec2.route_tables",
"ec2.security_groups",
"ec2.subnets",
"ec2.transit_gateways",
"ec2.vpc_endpoints",
"ec2.vpc_peering_connections",
"ec2.vpcs",
"ec2.vpn_gateways",
"ecr.repositories",
"ecs.clusters",
"ecs.task_definitions",
"efs.filesystems",
"eks.clusters",
"elasticbeanstalk.applications",
"elasticbeanstalk.environments",
"elasticsearch.domains",
"elbv1.load_balancers",
"elbv2.load_balancers",
"elbv2.target_groups",
"emr.block_public_access_configs",
"emr.clusters",
"fsx.backups",
"guardduty.detectors",
"iam.accounts",
"iam.groups",
"iam.openid_connect_identity_providers",
"iam.password_policies",
"iam.policies",
"iam.roles",
"iam.saml_identity_providers",
"iam.server_certificates",
"iam.users",
"iam.virtual_mfa_devices",
"iot.billing_groups",
"iot.ca_certificates",
"iot.certificates",
"iot.policies",
"iot.streams",
"iot.thing_groups",
"iot.thing_types",
"iot.things",
"iot.topic_rules",
"kms.keys",
"lambda.functions",
"lambda.layers",
"lambda.runtimes",
"mq.brokers",
"organizations.accounts",
"rds.certificates",
"rds.cluster_parameter_groups",
"rds.cluster_snapshots",
"rds.clusters",
"rds.db_parameter_groups",
"rds.db_security_groups",
"rds.db_snapshots",
"rds.db_subnet_groups",
"rds.event_subscriptions",
"rds.instances",
"redshift.clusters",
"redshift.subnet_groups",
"route53.domains",
"route53.health_checks",
"route53.hosted_zones",
"route53.reusable_delegation_sets",
"route53.traffic_policies",
"s3.accounts",
"s3.buckets",
"sagemaker.endpoint_configurations",
"sagemaker.models",
"sagemaker.notebook_instances",
"sagemaker.training_jobs",
"secretsmanager.secrets",
"sns.subscriptions",
"sns.topics",
"sqs.queues",
"ssm.documents",
"ssm.instances",
"waf.rule_groups",
"waf.rules",
"waf.subscribed_rule_groups",
"waf.web_acls",
"wafv2.managed_rule_groups",
"wafv2.rule_groups",
"wafv2.web_acls"
]
}
// Module Configurations
modules {
// drift configuration block
drift "drift-example" {
// state block defines from where to access the state
terraform {
// backend: "local" or "s3"
backend = "local"
// local backend options
// files: list of tfstate files
files = ["/path/to.tfstate"]
// s3 backend options
// bucket = "<tfstate bucket>"
// keys = [ "<tfstate key>" ]
// region = "us-east-1"
// role_arn = ""
}
// provider "aws" {
// account_ids = ["123456789"]
// check_resources = ["ec2.instances:*"]
// ignore_resources = ["ec2.instances:i-123456789", "aws_cloudwatchlogs_filters:*"]
// }
}
}
Once the above stuff is in place fire cloudquery fetch and it’ll start populating the SQL database by accessing the AWS inventory from all the accounts that’ve been configured in the config.hcl file.
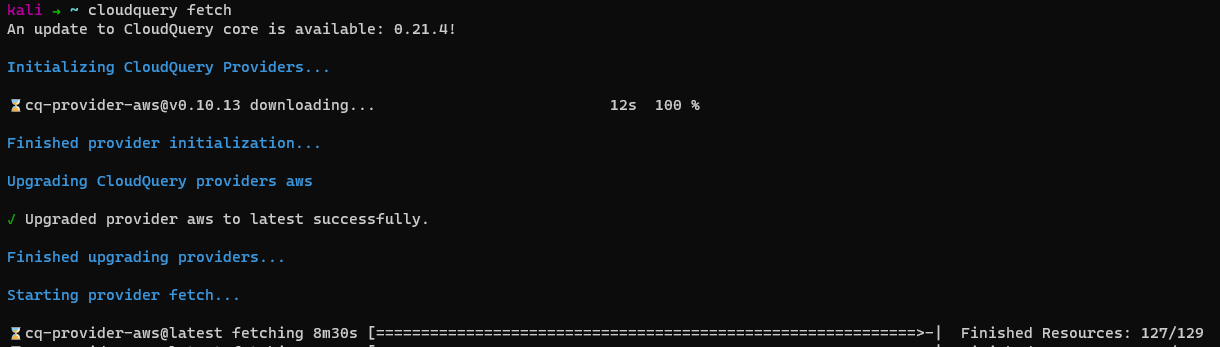
Extraction
Once the fetch command completes, open up your favourite PGAdmin console and fire the below SQL Query.
DO
$$
DECLARE
r RECORD;
tbl_name varchar;
data_exists boolean ;
BEGIN
FOR r IN SELECT table_name FROM information_schema.tables WHERE table_schema='public'
LOOP
tbl_name = r.table_name;
RAISE NOTICE '%',tbl_name;
EXECUTE format('select count(*) where exists (select 1 from %s)',tbl_name) INTO data_exists;
RAISE NOTICE '%',data_exists;
IF data_exists THEN
EXECUTE format('COPY %s TO ''%s'' WITH (FORMAT CSV, HEADER)',tbl_name,CONCAT('/tmp/',tbl_name,'.csv'));
END IF;
END LOOP;
END;
$$;
The Query above iterates through all the tables created by CloudQuery and exports only non-empty tables in CSV format. The tables aggregate resources from all accounts.
For Ex: if you have 5 S3 buckets , in 3 different accounts , CloudQuery will aggregate all the 5 S3 buckets as 5 rows and a column to desginate the associated account IDs.
End Result would be something like below in the directory from where you executed the docker command to spin up a PostgreSQL database.
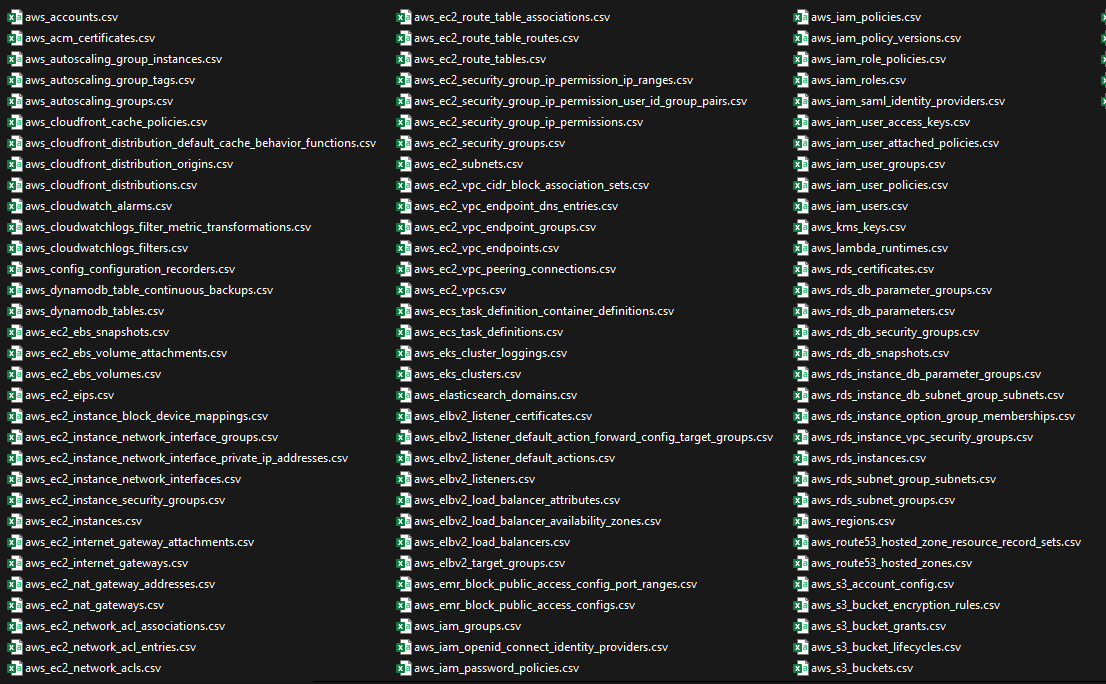
That’s all folks hope you find this post useful :-)
Rohit Salecha
Security Engineering
Rohit Salecha is a technology geek who loves to explore anything that runs and understands binary. As a security engineer he is passionate about learning the length,breadth and depth of technology. Being more on the defensive side he has evangelised secure software development at various organizations for more than a decade. He is ridiculously driven by “everything as code” mantra and strongly believes that security team must strive towards making themselves irrelevant.